Introduction
The primary goal of this project is to create a model that can accurately classify whether a social media comment is sarcastic or not. When given data containing a comment, parent comment, and topic, the model should be able to use this information in order to determine whether the the comment sentiment is sarcastic. Such a model could be incredibly important in the field of sentiment analysis as current NLP being used to understand subjective opinions doesn’t account for the fact that people may be sarcastic in their thoughts. This would entail that sentiment analysis cannot account for the intentions of people’s comments and needs to be more contextual. An application of this model would be for natural language bots/virtual assistants that may generate their own sarcastic comments to seem more human-like. The overall impact of this on NLP and sentiment analysis would be very helpful to understanding further conversational, contextual analysis done by AI.
Methods
The training data that we plan to use for this comes from the following:
- Kaggle - Detect Sarcasm in Comments
- Kaggle - Sarcasm on Reddit
- Corpus of Sarcasm in Twitter Conversations
Our data consists solely of tweets and comments on Reddit. The datasets provided by Kaggle contain over 1 millions preprocessed comments and other data. Our model will likely be trained by splitting the dataset into a train and test group. Another possible way for us to run this is by training it on one dataset and then testing it on others to find its accuracy.
Our current plan is to take a variety of popular NLP algorithms like LSTM (long short-term memory) or BERT (Bidirectional Encoder Representations from Transformers) and modify them so that they can better detect sarcasm from multiple input strings. Another idea may be to analyze contextual sentences for keywords and underlying sentiment as sarcastic comments will likely have the opposite tone. This is subject to change as more research into this topic may reveal that there would be a more optimal way to implement a sarcasm detector.
Unsupervised Learning with KMeans Clustering
In order to understand and visualize our data better, we took a multi-step approach to building an unsupervised Machine Learning Model. A detailed explanation of your code and reasoning can also be found in this Google Colaboratory Notebook:
Data Preprocessing
For our project, we primarily relied on the NLTK libraries which is commonly used for natural language processing.
The dataset that we performed our algorithms on was the reddit dataset from Kaggle that contained around 150,000 sarcastic and non-sarcastic comments. The dataset contained the following features for each comment: user ID, text of the comment, data, down, parent comment, score, top, date, topic, user name, and label. The labels are binary where 1’s represent a sarcastic comment and 0’s are not sarcastic.

The left bar of this graph shows the amount of non-sarcastic comments and the right bar shows the amount of sarcastic comments. The frequency of each in our dataset is roughly the same so the class distribution is not skewed.
The features that we dropped from our dataset due to irrelevance were User ID, comment date, no. of downvotes, top, and the username. We also decided to see if there was a correlation between sarcastic comments and upvotes but it doesn’t appear to be that way according to this scatterplot.

Therefore, we also dropped upvote score. This left our dataset with only text data.
Text Processing
In order to preprocess the text data, we needed to start by getting rid of unnecessary words and punctuation in the text. Punctuation is highly variable when used in sentences and stop words like “the” or “and” contribute very little to the meaning of the sentence so we should remove those as well. NLTK has a stop words library that we used to clean the text. This is the result of a sentence before and after text cleaning.
Original: Yay! That's amazing!
Modified: ['yay', '!', 'thats', 'amazing']
Then, we decided to use word embeddings to represent sentences as n-dimensional vectors. Using word2vec, a popular algorithm for vectorizing text, we can determine the similarity of sentences using a cosine similarity function on the embeddings.
In order to generate a vectorized representation of each comment in our dataset, we trained a neural network to create a 200 by 1 representation of each comment. We trained the model by using randomly selected 4000 comments from our original dataset. The vectorized representation of the comments do not contain outliers as unique words would be the only factor that generates an outlier but words that weren’t used more than 5 times were not counted in the vectorization.
K Means Algorithm and Elbow Method
The unsupervised learning algorithm that we used for this part of the project was the K means algorithm which attempts to find the optimal number of clusters that can be used to minimize the loss function which is defined as the summation of the distances between the centers and the other data points. We used the elbow method to determine the optimal number of clusters and used the Sci-kit Learn implementation of the K means algorithm. We generated the following graph after running K means with a max iteration of 1000 and up to 75 clusters.
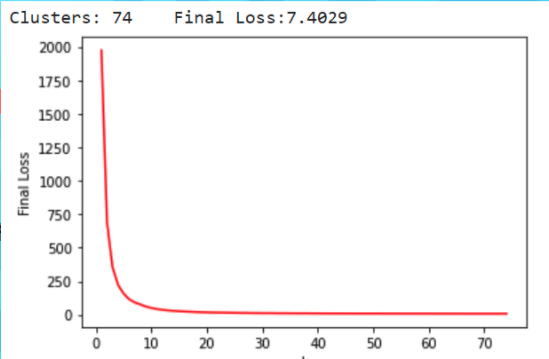
Based on the above graph, the optimal number of clusters seems to be between 10 and 20. We can estimate that it is 15.
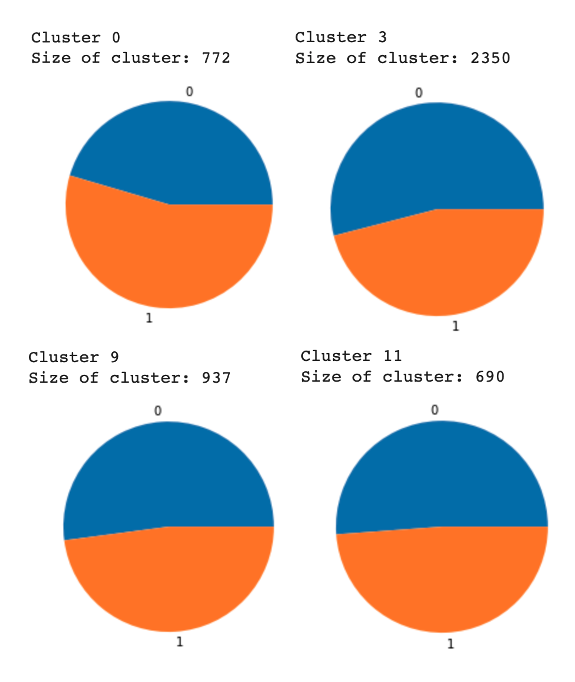
After determining the optimal number of clusters, we drew a comparison between the unsupervised algorithm and the labeled data using the results from the K means algorithm for 15 clusters. For the clusters, there was no defining way to separate sarcastic comments from non-sarcastic comments using this implementation. Pictured below are some of the clusters where blue represents the non-sarcastic comments and orange represents the sarcastic comments. All of the clusters looked very similar to the images below.
Summary of Unsupervised Learning Findings
The K means algorithm did not prove to be an effective method for sarcasm detection as the clusters that we seemed to generate after determining the optimal number of clusters did not seem to organize the comments decisively. Intuitively, the reason for this would be a result of our text preprocessing algorithm. The points similarity does not indicate anything when using Euclidean distance between them but only when put through the cosine similarity function. Instead of using linear distance as the metric for determining loss in the K means algorithm, we could use the cosine function instead. This would be an area for us to look into over the following few weeks and may be more informative than the standard K means algorithm.
Supervised Learning with Logistic Regression
Text/Data Preprocessing
For the supervised learning portion of the assignment, we used the same preprocessing that we did for the unsupervised portion. To reiterate, we pulled our data from a GitHub link where we had stored the dataset and put it in a data frame, dropped the unnecessary or uncorrelated features, got rid of punctuation and stop words, and used the Doc2Vec model to vectorize comments. Because this is a supervised learning approach, we also split up our data into a training and testing set. 80% of the comments (12,000) went towards the training data and the other 20% went towards the test data.
Model Architecture
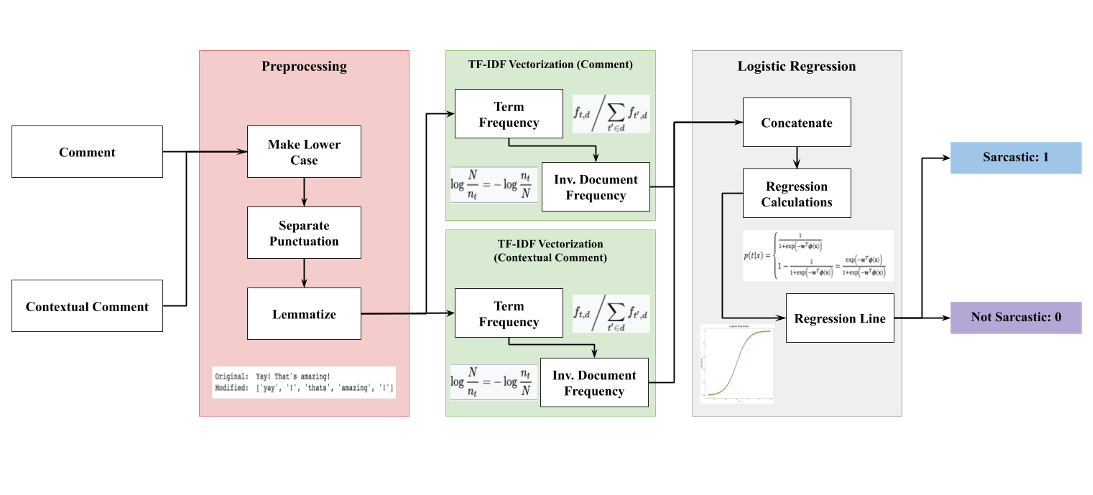
After testing between a variety of supervised learning methods, the model that had the highest accuracy rate used logistic regression to classify the comments. Each comment and parent comment are represented as a vector for different n-grams (short phrases of words) found in the text data. In order to perform logistic regression, we wanted to measure how important each word was to the overall meaning of the sentence for greater accuracy. We decided to use TF-IDF vectorization on the preprocessed input which stands for term-frequency inverse document frequency. Term frequency calculates the amount of times a word appears in a given document but would undoubtedly give weight to meaningless words like “the” or “a.” To offset for this, it is multiplied by inverse document frequency which measures how much information the word provides to the meaning of the document. TF-IDF is one of the most common term weighting systems used in NLP. The pipeline we used was as follows:
- Preprocessed Input
- TF-IDF Vectorization
- Logistic Regression on the concatenated input of the parent and original comment
- Output: 0 for not sarcastic and 1 for sarcastic
Here is a visualization of the pipeline:
Results and Analysis
In order to visualize the results of our model, we used the ELI5 library to picture the classification process by the model. Below is a table containing the weight of each n-gram received after training. In other words, it indicates which words are more likely to be used in sarcastic comments. Certain words like “yeah” or “!” were found to be very indicative of sarcasm.

Additionally, we also have a confusion matrix displaying the accuracy of the model and the rate of false positives and negatives:

Our model was able to predict whether or not a comment was sarcastic roughly 70% of the time. We determined that this was successful because it was significantly greater than random chance. Additionally, a lot of humans themselves struggle on picking up sarcasm all the time, so 70% seems to be a very realistic ballpark for a successful model.
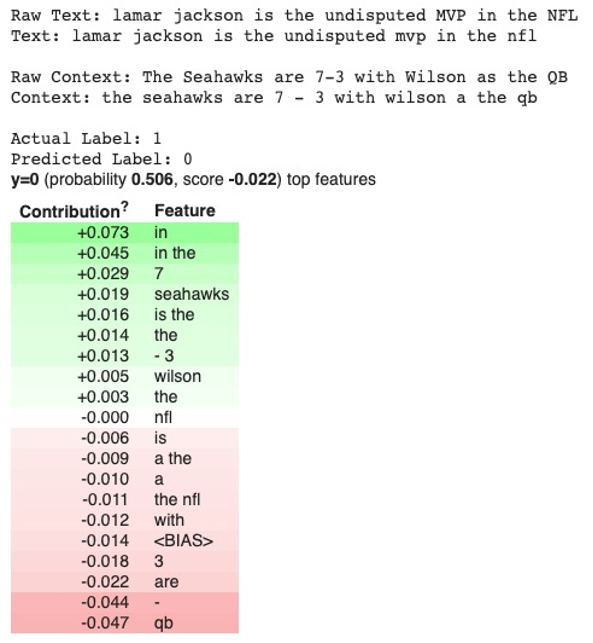
The last action item we took was testing our own sarcastic comments on the model we generated. One of the tests we performed was giving the model the sentence “Russell Wilson is the undisputed MVP in the NFL” which we labeled as sarcastic because in the best case it is between him and Patrick Mahomes. The parent comment we gave was “The Seahawks are 7-3 with Wilson as the QB.” The model correctly predicted that it was a sarcastic comment to our own amusement but if we switched out the name for another NFL quarterback, it was determined to be not sarcastic. This is an example of what testing a comment would look like.
Discussion
Through our analysis using Logistic Regression, more than being able to develop a model that can accurately predict sarcasm using context clues, we were able to analyze comments to find what terms and bigrams offer the most insight into whether a comment is sarcastic or not. We can compare these findings to our intuitive understanding of use cases of sarcasm, As we see in the charts, our model was correctly able to determine that usages of certain terms in text can lead to a higher sarcasm rate, which means that we can use this understanding to judge a comment by scoring it using each terms weight.
This research is likely very useful in more complex Natural Language Processing scenarios, as now we can use our insight to not only assist those in determining the truthfulness of statements, but to also help teach bots what to look for in human speech in order to best respond to it. Using this sarcasm detection in tandem with other sentiment analysis tools and models will advance our research and development of natural language processing tools.
References
- https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/reports/custom/15791781.pdf
- https://www.aclweb.org/anthology/C14-1022.pdf
- http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.800.4972&rep=rep1&type=pdf
- https://www.kaggle.com/yantiz/a4-demo-sarcasm-detection-with-logit
Touch-Point 1 Deliverables
Project Proposal Video: https://bluejeans.com/s/tjvlm
Project Proposal Slide (Slide 1): https://docs.google.com/presentation/d/1DiOc0nDUfCwI1mvO6MIp_5j9UZTssN1W7Jh6VkHPBsA/edit?usp=sharing
Touch-Point 2 Deliverables
Video Summary: https://bluejeans.com/s/3_3kj
Video Slide (Slide 2): https://docs.google.com/presentation/d/1DiOc0nDUfCwI1mvO6MIp_5j9UZTssN1W7Jh6VkHPBsA/edit?usp=sharing
Colab Notebook: sarcasm_unsupervised.ipynb
Touch-Point 3 Deliverables
Video Summary: https://bluejeans.com/s/Emez0QInFV8
Final Project Presentation: https://bluejeans.com/s/ha8RB7CtAWq/
Video Slide (Slide 3): https://docs.google.com/presentation/d/1DiOc0nDUfCwI1mvO6MIp_5j9UZTssN1W7Jh6VkHPBsA/edit?usp=sharing
Colab Notebook: sarcasm_supervised.ipynb